Lecture 01: Introduction to Neural Networks
Section 1: Function Approximators


At the beginning of each section, I present review questions that capture the main ideas. I show them upfront so you know what to focus on while listening. Then at the end of each section, we review them. This repeated exposure -- preview, lecture, review -- is designed to maximize retention of the core concepts.
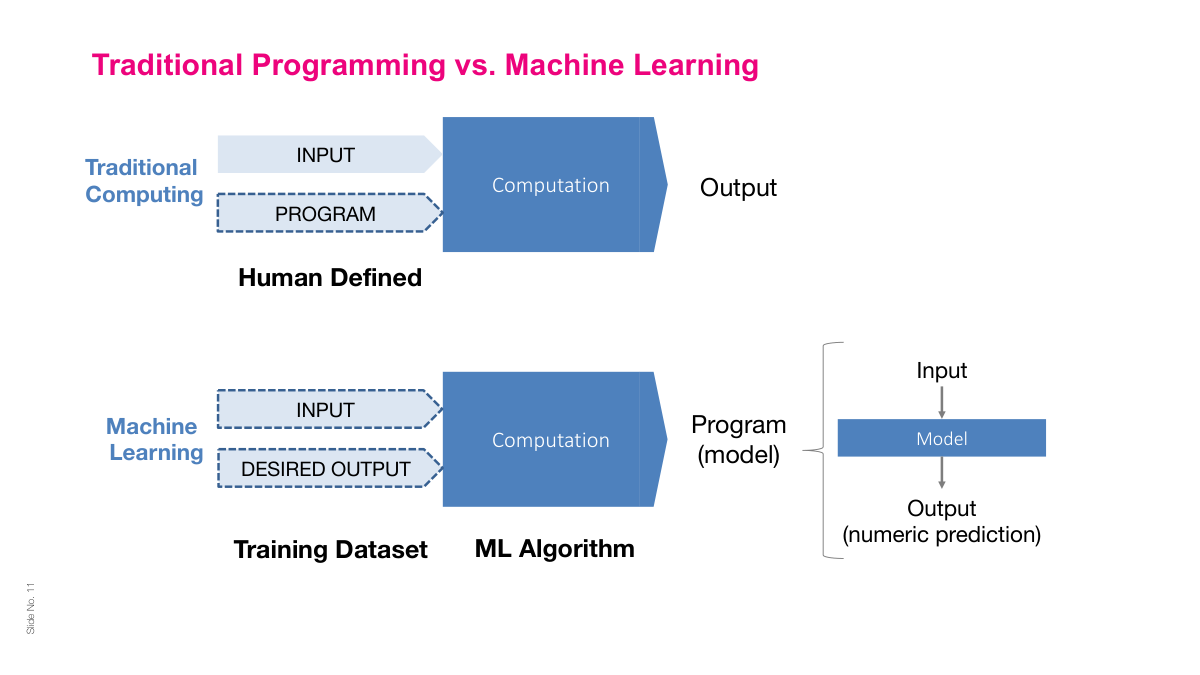
In machine learning, I think of models as function approximators. A function maps each element in a domain to a single element in the range. In supervised ML, we have data points with inputs and corresponding outputs, and our goal is to learn a function that approximates the true relationship between them. However, observed data may not be a function -- one x may map to multiple y's. So we think of it as function approximation: finding a function that "fits" the data according to some mathematical objective function. This is only one of many ways to view ML -- you could also approach it probabilistically, algorithmically, or as optimization -- but function approximation is the most practical lens for understanding what we're doing.

Start with the simplest function approximator: a linear function. Inputs have many names -- features, regressors, covariates, independent variables -- and you should use these interchangeably depending on your audience. Outputs are called observations, response variables, labels, or target variables. The simplest model is a line with two parameters -- slope and intercept. But linear models are rigid. Two parameters provide limited flexibility, and virtually no interesting real-world problem is truly linear. Images, language, speech -- these all involve deeply nonlinear patterns.

We can add polynomial features like x squared and x cubed for more flexibility -- now we have four parameters and three features, where each feature is a function of our original covariate. The blue curve fits the data better than a straight line. But this requires manual feature engineering: you need intuition to produce the right transformations of your raw data. With hundreds of input variables, this becomes impractical. You'd need to guess which polynomial terms, interactions, and transformations might be useful. This is exactly the problem neural networks solve.

A neural network introduces two key ingredients. First, a non-linear activation function -- ReLU is the standard: max(0, x), applied element-wise. This is what makes neural networks fundamentally different from stacking linear layers. Second, a "hidden layer" function that computes ReLU of a weight matrix times the input vector plus a bias vector. The weight matrix W contains d times n parameters, and the bias vector adds n more. Even a single hidden layer introduces substantially more learnable parameters than a simple linear model. This is the basic building block we'll compose into deeper networks.
Here's the payoff. A five-hidden-layer neural network with 500 units per layer, taking a single input x, has over a million parameters. The green curve shows its fit -- far better than linear regression or the polynomial, though it likely overfits in this example. The key insight: neural networks are good function approximators because they're easy to scale. Just add layers or neurons, and the network gains more flexibility to model complex data distributions. No need for any manual feature engineering -- the network learns the right representations automatically. This scalability is exactly what the field has exploited, and it's why NVIDIA's stock has skyrocketed.
Let's review. A parameter is any learnable number in the model -- analogous to the slope and intercept in linear regression. Linear functions are poor function approximators because they have too few parameters and can only capture linear relationships. Neural networks overcome this through their layered structure: compose multiple hidden layers with non-linear activations, and you get a flexible function approximator that scales straightforwardly with more parameters, more compute, and more data.
Section 2: Basics of Feed Forward Neural Networks
Section 2 digs into the mechanics of feed-forward neural networks -- also known as multi-layer perceptrons, deep feedforward networks, dense neural networks, or fully connected neural networks. Same architecture, many names. You'll see all of these in the literature, so get comfortable with them.

The key questions for this section: Can you define the core terminology -- input layer, output layer, hidden layer, bias, activation function, perceptron, width, and depth? What makes a perceptron different from a linear function? What considerations matter when picking an output activation function? And what are the other names for feed-forward neural networks? Keep these in mind as we go through the material.
A perceptron takes inputs, multiplies each by a learnable weight, sums them up with a bias term, then passes the result through a non-linear activation function. The weights are akin to learning the "slope" and the bias is the "intercept." The sum is a weighted combination: sigma of (W transpose x plus b). The activation function is what makes this more than just a linear function -- without it, stacking layers would still only represent a linear transformation. Common activation functions include sigmoid, tanh, and ReLU. My general advice: start with ReLU. It works well in most cases and its derivative is trivially easy to compute.
The three common activation functions: sigmoid squashes output to (0,1), tanh maps to (-1,1), and ReLU clips negatives to zero and passes positives through unchanged. The non-linear activation is what allows a perceptron to learn "interesting" functions. And the more perceptrons you stack together, the more interesting and complex the functions you can learn. This is the core insight behind scaling neural networks -- just add more units and layers.
Here's the simplest possible neural network: two inputs, one hidden neuron, one output. The input layer represents your features -- these aren't computation units, they just pass data in. The hidden layer contains the actual perceptrons doing computation. The output layer produces the final prediction. This network has depth 2 (hidden + output), width [2, 1, 1], and 5 parameters: (12+1) + (11+1) = 5. Count the parameters by looking at connection weights between layers, then add one bias per neuron.

Now add more perceptrons. Two inputs, one hidden layer of three neurons, two outputs. Depth is 2, width is [2, 3, 2]. Parameter count: (32+3) + (23+2) = 17. The compact form is W2 times sigma of (W1*x + b1) + b2. I deliberately write out every individual weight here -- W1,1,1, W1,1,2, and so on -- so it's obvious what's happening. But going forward, people use matrix form directly. You need to get comfortable reading matrix notation because as networks get larger, you can't write out every weight explicitly.

Three inputs, three hidden layers of four neurons each, three outputs. Depth is 4, width is [3, 4, 4, 4, 3], and the parameter count is (43+4) + (44+4) + (44+4) + (34+3) = 71. The function is nested compositions: W4 times sigma of W3 times sigma of W2 times sigma of (W1*x + b1) + b2) + b3) + b4. Each layer adds its own weight matrix and bias, with an activation function in between. The pattern is always the same -- you're just stacking more of them.
This is what a "deep" neural network looks like. Five inputs, 10 hidden layers of 10 neurons each, 5 outputs. Depth is 11, and the parameter count is 1,105. The word "deep" in deep learning literally means many layers -- and the definition of what counts as deep keeps shifting as we build bigger networks. What used to be considered deep is now shallow by modern standards. Each additional layer gives the network another opportunity to learn more abstract representations, and because the underlying computation is just matrix multiplications and activation functions, it scales straightforwardly with more compute.
The output neurons model the y values -- your labels or targets. The activation function on the output layer should match your response variable. Key considerations: is it a regression or classification problem? What's the range of the output? Is it discrete or continuous? We'll look at four common activation functions for output units: identity (for unbounded real-valued outputs), ReLU (for positive real-valued outputs), sigmoid (for binary classification), and softmax (for multi-class classification). The choice of output activation determines what kind of predictions your network can make.
For linear output, use the identity activation -- the output is just the raw value from the linear combination, y = W transpose h + b. This gives you real-valued output in the range negative infinity to positive infinity, appropriate for general regression problems. For positive real-valued output, use ReLU on the output unit: y = ReLU(W transpose h + b). This clips negative values to zero, giving output in [0, infinity). Use this when your target is something that can't be negative, like a price or a count.

For binary output, use sigmoid on the output unit -- it squashes the result to a probability between zero and one. The output variable is the probability of the "1" label. This is what you want for yes/no classification problems. For categorical output with multiple classes, use softmax across multiple output units. Softmax ensures all outputs are in [0,1] and sum to one, giving you a proper probability distribution across N categories. For example, if you're classifying colors -- red, green, blue, yellow -- you'd have four output units with softmax. The choice of output activation is one of the key architectural decisions you need to get right.

Let's review the key terminology. Input layer: your features, not real neurons. Hidden layer: where the computation happens -- perceptrons with weights, biases, and activation functions. Output layer: produces final predictions. A perceptron differs from a linear function because of the non-linear activation. To count parameters: count every connection weight between adjacent layers, then add one bias per neuron. For picking an output activation function, match it to your problem type -- identity for regression, ReLU for positive values, sigmoid for binary, softmax for categorical. And remember the many names: feed-forward neural networks, multi-layer perceptrons, dense networks, fully connected networks -- all the same thing.
This first section covers the most practical lens for understanding machine learning: function approximation. We'll answer three key questions -- what is a parameter, why are linear functions poor function approximators, and why are neural networks good ones.